android鋼琴源碼(谷歌推出全能扒譜AI:只要聽一遍歌曲,鋼琴小提琴的樂譜全有了)


曉查發自凹非寺
量子位報道|公眾號QbitAI
聽一遍曲子,就能知道樂譜,還能馬上演奏,而且還掌握“十八般樂器”,鋼琴、小提琴、吉他等都不在話下。
這就不是人類音樂大師,而是谷歌推出的“多任務多音軌”音樂轉音符模型MT3。
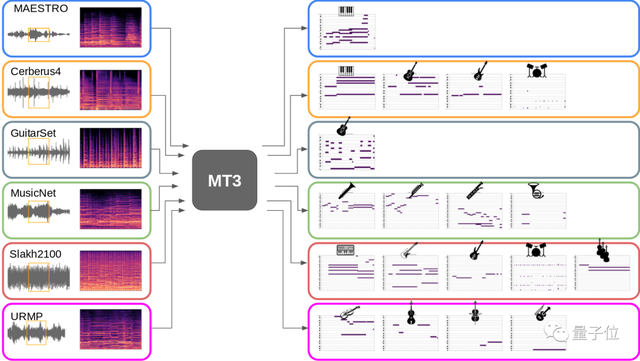
首先需要解釋一下什么是多任務多音軌。
通常一首曲子是有多種樂器合奏而來,每個樂曲就是一個音軌,而多任務就是同時將不同音軌的樂譜同時還原出來。
谷歌已將該論文投給ICLR2022。
還原多音軌樂譜
相比于自動語音識別(ASR),自動音樂轉錄(AMT)的難度要大得多,因為后者既要同時轉錄多個樂器,還要保留精細的音高和時間信息。
多音軌的自動音樂轉錄數據集更是“低資源”的。現有的開源音樂轉錄數據集一般只包含一到幾百小時的音頻,相比語音數據集動輒幾千上萬小時的市場,算是很少了。
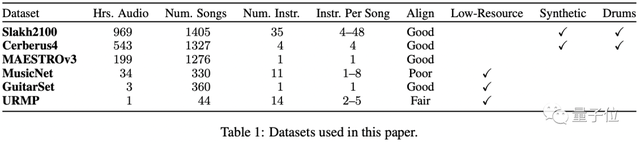
先前的音樂轉錄主要集中在特定于任務的架構上,針對每個任務的各種樂器量身定制。
因此,作者受到低資源NLP任務遷移學習的啟發,證明了通用Transformer模型可以執行多任務AMT,并顯著提高了低資源樂器的性能。
作者使用單一的通用Transformer架構T5,而且是T5“小”模型,其中包含大約6000萬個參數。
該模型在編碼器和解碼器中使用了一系列標準的Transformer自注意力“塊”。為了產生輸出標記序列,該模型使用貪婪自回歸解碼:輸入一個輸入序列,將預測出下一個出現概率最高的輸出標記附加到該序列中,并重復該過程直到結束。
MT3使用梅爾頻譜圖作為輸入。對于輸出,作者構建了一個受MIDI規范啟發的token詞匯,稱為“類MIDI”。
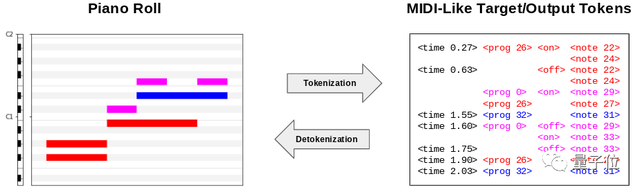
生成的樂譜通過開源軟件FluidSynth渲染成音頻。
此外,還要解決不同樂曲數據集不平衡和架構不同問題。
作者定義的通用輸出token還允許模型同時在多個數據集的混合上進行訓練,類似于用多語言翻譯模型同時訓練幾種語言。
這種方法不僅簡化了模型設計和訓練,而且增加了模型可用訓練數據的數量和多樣性。
實際效果
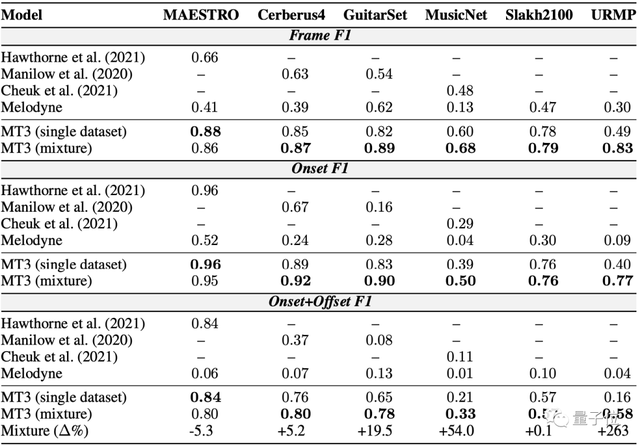
在所有指標和所有數據集上,MT3始終優于基線。
訓練期間的數據集混合,相比單個數據集訓練有很大的性能提升,特別是對于GuitarSet、MusicNet和URMP等“低資源”數據集。
最近,谷歌團隊也放出了MT3的源代碼,并在HuggingFace上放出了試玩Demo。
不過由于轉換音頻需要GPU資源,在HuggingFace上,建議各位將在Colab上運行JupyterNotebook。
論文地址:
https://arxiv.org/abs/2111.03017
源代碼:
https://github.com/magenta/mt3
Demo地址:
https://huggingface.co/spaces/akhaliq/MT3








最新資訊
-

二胡刀刃如夢簡譜,二胡刀刃如夢簡譜完整版
2024-09-09 11:22:33 -

小桃仙小提琴詞,桃小仙 小提琴
2024-09-09 11:21:51 -

薩克斯彈奏魂斷藍橋,薩克斯演奏魂斷藍橋
2024-09-09 11:12:24 -

鄉村小吉薩克斯,薩克斯鄉村小路
2024-09-09 11:08:29 -

幾斗小提琴伴奏,幾斗小提琴譜
2024-09-09 11:07:48 -

玫瑰少年薩克斯中音,玫瑰少年薩克斯中音簡譜
2024-09-09 10:38:02 -

小提琴的潛在價值,小提琴的潛在價值是什么
2024-09-09 10:37:39 -

薩克斯上不來氣,吹薩克斯上氣不接下氣怎么辦
2024-09-09 10:24:45 -

薩克斯名曲愛情天堂,薩克斯名曲愛情天堂演奏視頻
2024-09-09 10:20:57 -

北京天壇二胡修理,北京天壇二胡修理店
2024-09-09 10:01:13
熱門資訊
-

小松林鋼琴伴奏(鋼琴聲聲(詩歌十首)北京 張新貴)
2024-07-05 13:54:01 -

二胡獨奏西口韻(新民歌:西口口的女女好大的腳)
2024-07-02 16:29:29 -

怎么區分鋼琴中幾級音高(鋼琴國際標準音高440HZ的發展歷史)
2024-06-26 18:33:35 -

女人和男生坐鋼琴旁(C羅女友拎愛馬仕坐鋼琴旁,打造優質名媛范,比超模伊蓮娜有人氣)
2024-06-14 05:45:38 -

泊頭市水鋼琴南區(滄州高質量繪制文旅融合壯美畫卷)
2024-06-13 02:13:27 -

二胡演奏家金玥多大(被湖南衛視華人春晚“新”動到了)
2024-06-08 13:17:48 -

好聽的薩克斯樂曲五線譜(【小崔隨談】薩克斯如何看簡譜以及五線譜)
2024-06-05 12:00:12 -

昨日重現薩克斯獨奏肯尼基(優秀本科生|李書婷與室內樂、民族小樂隊、雙排鍵和電音樂隊)
2024-05-16 10:26:28 -

二胡獨奏臺灣人民幣解放(紅歌金曲聯奏14(二胡版))
2024-05-02 15:10:10 -

bundy美國薩克斯(選擇薩克斯樂器的注意事項以及方法(上))
2024-04-20 00:35:16




